

Using AI to generate insights and actionable next steps from MMM data
Aditya Puttaparthi Tirumala from Zillow takes us through on how to build an AI co-pilot to help marketing teams make better and faster decisions from MMM insights.


First things first: this article is co-written with Aditya Puttaparthi Tirumala. He’s Principal Data Scientist at Zillow, leading R&D in Brand and Marketing Data Science. His team builds AI-powered measurement systems using ML, MLOps, and Generative AI. A recognized expert in marketing measurement, he partners with leaders on strategy and will share insights on Generative AI’s impact on the field in this article.
MMM alone isn’t enough anymore
Marketing Mix Models (MMMs) are making a comeback.
As privacy restrictions tighten and cookies crumble, marketers are returning to MMMs as one of the few durable, privacy-safe ways to measure performance. But this resurgence is happening in a very different landscape: one where data volumes have exploded, leadership expectations from models have increased, model complexity has increased, and decision timelines have collapsed.
This is where Large Language Models (LLMs) come in. AI-assisted tools (or “AI Co-pilots”) are emerging as powerful accelerators inside marketing science workflows.
They can:
Automate data extraction and summarization
Translate complex model results into plain language
Identify anomalies or shifts across time
Draft first-pass performance memos and recommendations
With the right setup, these tools can shrink a multi-week storytelling process down to days or even hours. But this speed introduces a new problem: reliability.
Why now?
MMMs remain one of the go to tools for long-term performance measurement in marketing since the 50s, but they come with a major bottleneck: human interpretation.
A typical MMM produces dozens of outputs: incrementality, contribution numbers, Cost Per Actions, marginal ROIs, diminishing returns (response curves), confidence intervals, stability loops. All these at levels of granularity such as date/week/month, line of business, product, platform, region etc. Turning those numbers into something actionable takes both technical expertise and a storytelling skill. And, Data Scientists have been masters of that craft for a while! However, it takes a lot of time.
Even in well-staffed analytics teams, the process looks like this:
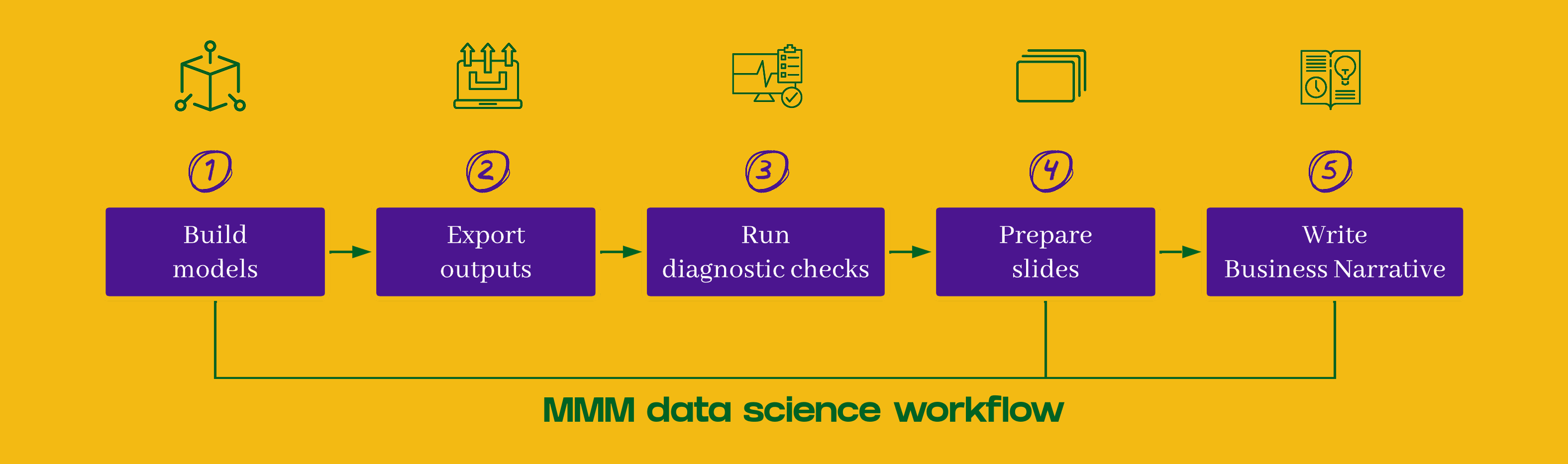
That can easily take 1–3 weeks per cycle.
In a fast-moving marketing environment, that delay means insights often arrive after the budget decisions have already been made.
Worse, MMMs can be opaque to non-technical teams. Marketers and finance leaders see tables of coefficients but lack context: Which channel truly moved the needle? How reliable is this estimate? How does this change if we shift spend mid-quarter?
MMMs can be opaque to non-technical teams. Marketers and finance leaders see tables of coefficients but lack context: Which channel truly moved the needle? How reliable is this estimate? How does this change if we shift spend mid-quarter?
Without faster and more interpretable translation, MMMs risk becoming beautiful models that never influence real decisions.
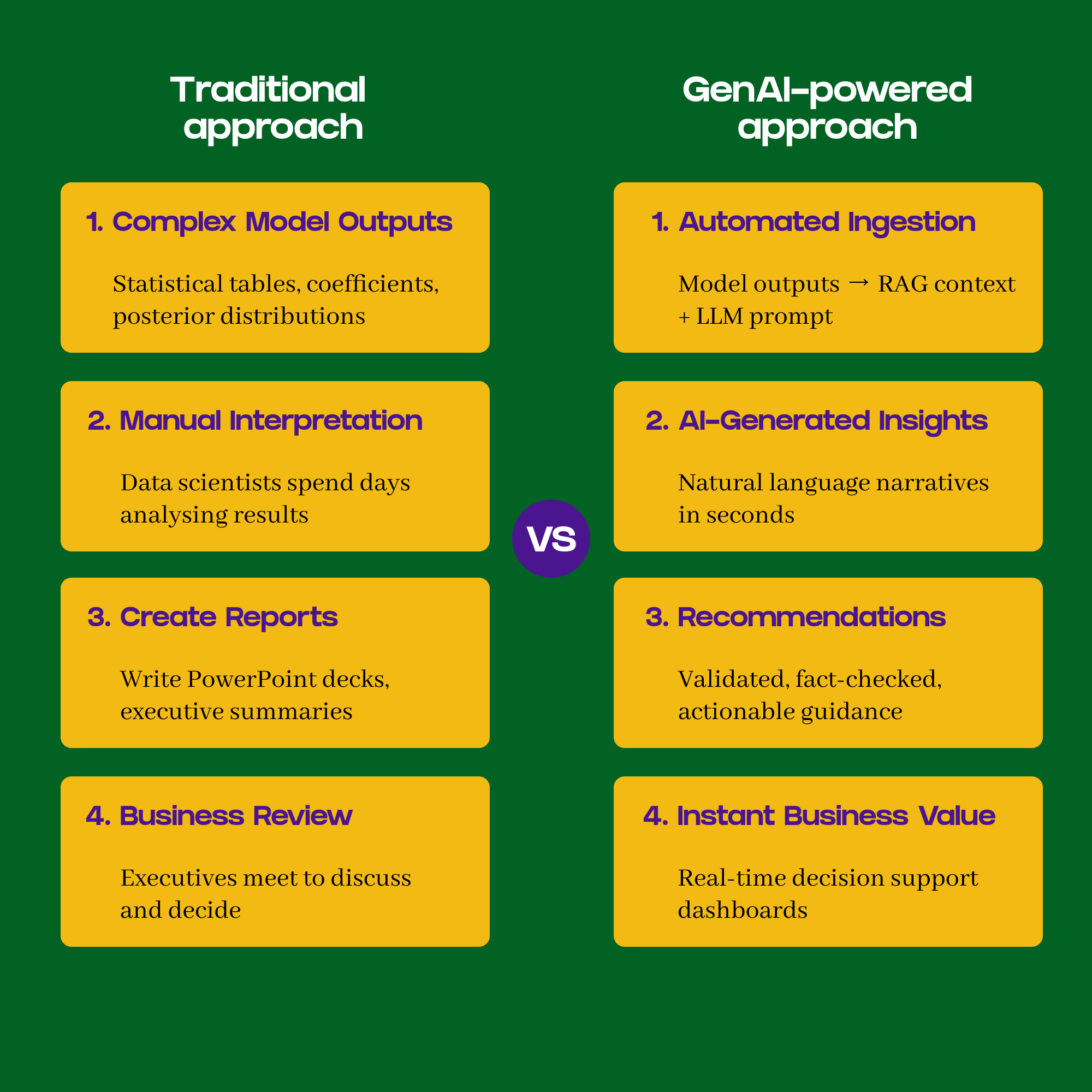
The role of LLM co-pilots in MMM workflows
The Promise of AI Assistance: The Rise of AI Co-pilots in Marketing Measurement
Marketing Mix Models (MMMs) have traditionally been data-intensive, slow to iterate, and hard to communicate. But with the rise of Large Language Models (LLMs), nearly every step of the MMM workflow is seeing automation or augmentation. LLMs fit in different parts of the MMM lifecycle:
Coding Assistance: LLMs can accelerate model development by helping Data Scientists write, debug, and refactor code for econometric and Bayesian MMM frameworks.
Missing Data Imputation: LLMs can suggest or generate plausible values using contextual and temporal patterns.
Data Summarization: Automatically describing correlation structures, feature interactions, and trends.
Agent-based Feature Engineering: LLM “agents” can propose, test, and evaluate new features or priors.
Drift and Stability Detection: Monitoring model consistency across time windows or geographies.
Post-Processing and Insights Generation: Transforming raw model outputs into coherent business stories.
LLMs as Co-Pilots for Decision Makers
A single MMM can produce hundreds of coefficients, elasticities, and saturation curves. For most executives, this output is overwhelming. Traditionally, a Data Scientist spends days (often weeks) translating these outputs into narratives, recommendations, and visuals that business leaders can act on.
LLM-based insight co-pilots can dramatically compress this timeline. They can summarize results, highlight ROI inflection points, compare trade-offs across channels, and generate decision-ready insights in plain language. For non-technical audiences, these co-pilots become interpreters of complexity - helping teams understand why certain investments outperform others and where budget reallocations could yield the most lift.
The LLM co-pilot can generate key insights such as:
Cost Per Action (CPA), where applicable
Revenue breakdowns by channel, platform, region, and segment over time
Cost metrics: CPC (Cost Per Click) and CPM (Cost Per Thousand Impressions)
Diminishing returns curves reflecting non-linear media effectiveness
Important: Consistency in field names, schema, and metadata is critical for context-aware reasoning. The co-pilot must not misinterpret fields or mix metrics.
“LLMs can’t reason their way out of bad data.” Ensuring high-quality, validated inputs is essential for reliable outputs.
How LLM for MMM Looks in Practice
Leading organizations are now deploying LLM-powered apps that let marketers and analysts query their Marketing Mix Models (MMMs) in plain language - no code or manual digging required.
Once new MMMs are trained, MLops pipelines automatically push model outputs (ROI curves, elasticities, forecasts) into a secure, centralized database. The LLM co-pilot then retrieves the latest version, grounded in brand-specific context and governed by internal data policies.
Stakeholders can ask:
“How did paid social efficiency trend last quarter?”
and receive instant, explainable answers - complete with charts, uncertainty ranges, and source tags.

The result: insights are fresh, contextual, and conversational, reducing decision time cycles.
Data requirements for trustworthy co-pilots
To enable LLM-based co-pilots to provide actionable insights, MMM data must be structured, granular, and consistent. Specifically, the model requires:
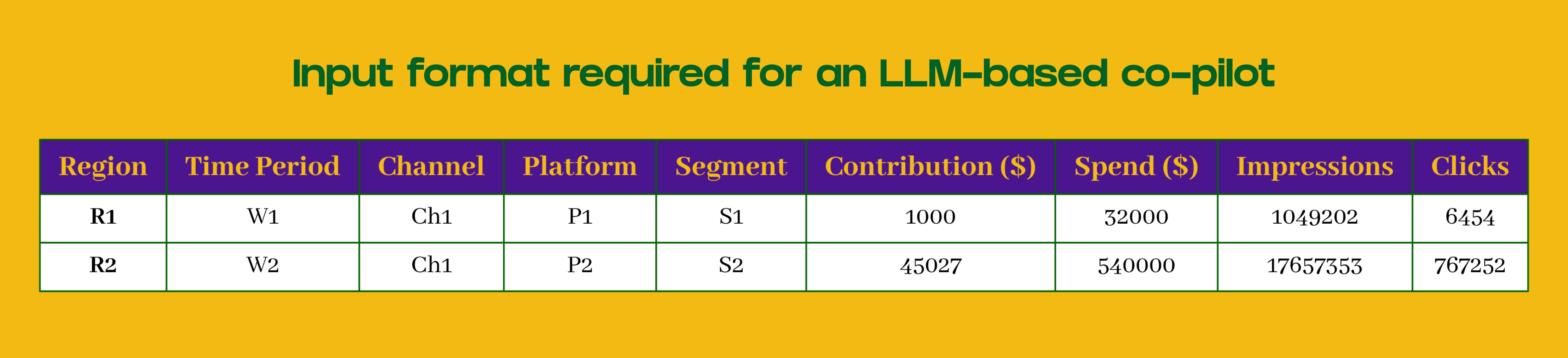
Channel × Platform × Time granularity: Typically monthly or weekly breakdowns.
Taxonomy information: If available, provide segment, product, or audience hierarchies.
Performance metrics: Spend, impressions, CPM/CPC changes, and predicted ROI or contribution at the same granularity.
Non-linear response curves: Include equations if available to capture diminishing returns or saturation effects. If not, the model can generate them by itself.
In practice, stakeholders need to provide data in a consistent schema, so the co-pilot can reason accurately. Many vendors, especially off-the-shelf models, do not provide this automatically. In most cases, in-house data teams can setup an automated connection with GenAI based applications for the model to tap into the latest model outputs. If this is not possible, the data can be loaded to the application as an excel file using which the model can generate insights and provide optimization recommendations.
Below is an example table illustrating the input format required for an LLM-based co-pilot:
Designing the co-pilot: prompt strategy & fine-tuning
Building a reliable LLM co-pilot for Marketing Mix Modeling requires not just structured data, but also explicitly engineered context so the model can reason accurately across multiple levels of granularity. This section describes how prompts, fine-tuning, semantic layers, and context engineering work together.
Prompt Engineering & Scaffolding
Prompts define the reasoning pathway of the model. Without careful design, LLMs can misinterpret or hallucinate insights. This can result in model producing incorrect recommendations and findings, which can ultimately result in bad business decisions.
Chain-of-Thought Reasoning: Break analysis into sequential steps.
Example: Instead of “Which channel is most efficient?”:
Compute CPA, CPC, and CPM for each channel.
Guardrails in Prompts: Explicit instructions to prevent errors:
“Always reference the source dataset and time period.”
Few-shot Prompting: Provide examples of correct MMM outputs to teach the model expected reasoning patterns.
Validation Queries: Embed self-checks in prompts:
“Does CPA equal Spend ÷ Conversions?”
Fine-Tuning on Brand-Specific Knowledge
Fine-tuning enables the model to understand brand-specific nuances, business rules, and historical performance patterns:
Historical MMM reports and campaign performance summaries. Load recent MMM results.
Business rules, e.g., minimum spend thresholds, segment-level filters, seasonality adjustments.
Embedding structured data (tables, JSON, CSV) for accurate metric referencing.

Fine-tuning ensures the LLM learns domain-specific language and patterns, reducing errors and improving consistency.
Semantic Layer: Structured Knowledge for the LLM
A semantic layer provides the model with a formal representation of the data and relationships, which is critical for consistent reasoning:
Entity definitions: What each field represents, e.g., Channel, Platform, Segment, Contribution.
Hierarchies & Aggregations: Define roll-ups (e.g., segment → region → country) for correct summations.
Valid Ranges & Constraints: Prevent impossible values (negative spend, CPC < 0).
Mapping to KPIs: Link data fields to ROAS, CPA, revenue contribution, etc.
Automatic Field Resolution: Prevents misinterpretation of similar metric names (e.g., “Spend” vs. “Budget”).
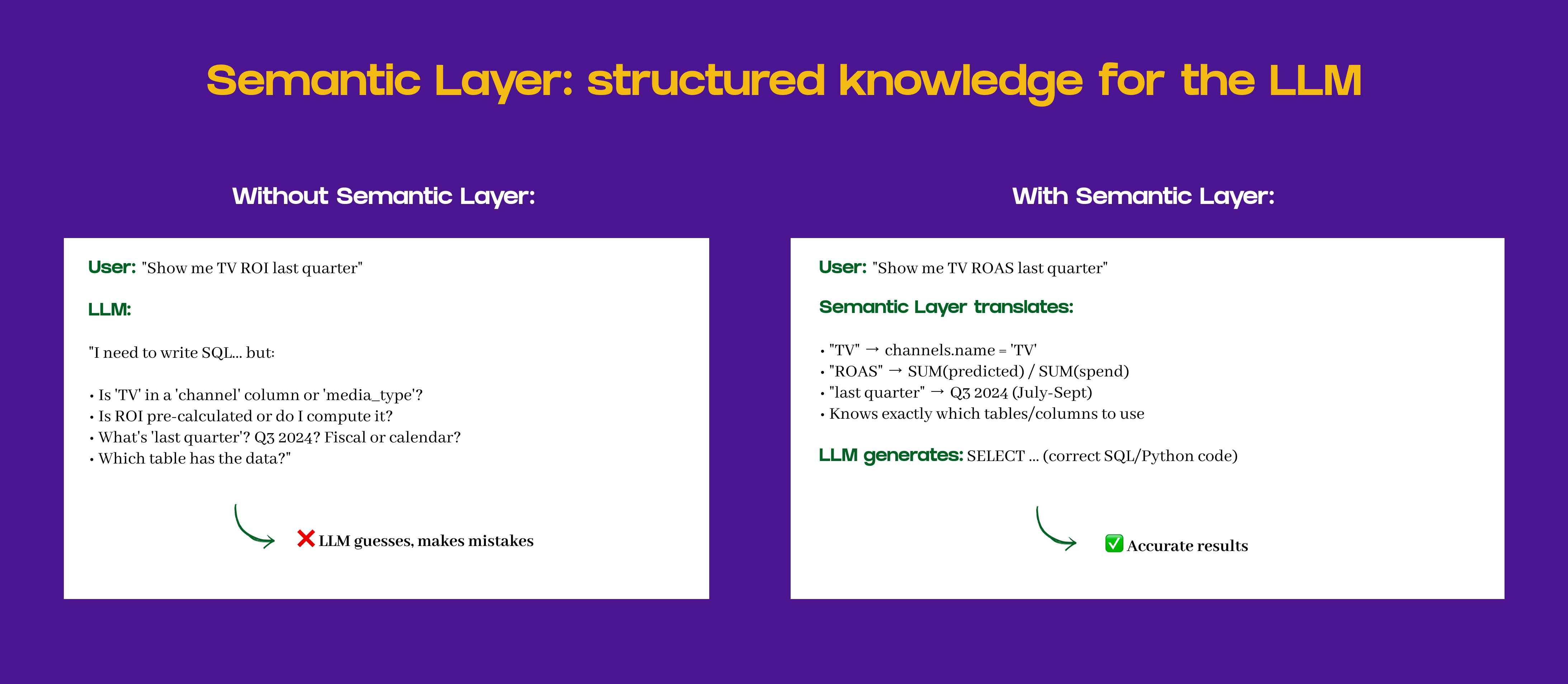
Semantic layers act as a knowledge graph for the co-pilot, ensuring data is interpreted consistently.
Context Engineering: Embedding Situational Awareness
Context engineering provides temporal, business, and domain context so the co-pilot can reason appropriately:
Temporal Context: Include campaign dates, seasonal periods, and event flags to distinguish baseline vs. incrementality effects.
Business Context: Define business objectives (ROAS, CPA targets, revenue goals) so the LLM aligns insights with decision-making priorities.
Data Provenance: Track source systems, calculation methods, and assumptions for transparency and traceability.
Scenario Context: Include multiple datasets (e.g., historical MMM, competitor benchmarks, media mix shifts) to provide situational grounding.
By embedding context explicitly, the co-pilot avoids common pitfalls like misreading coefficients, ignoring seasonal effects, or misattributing campaign impact.
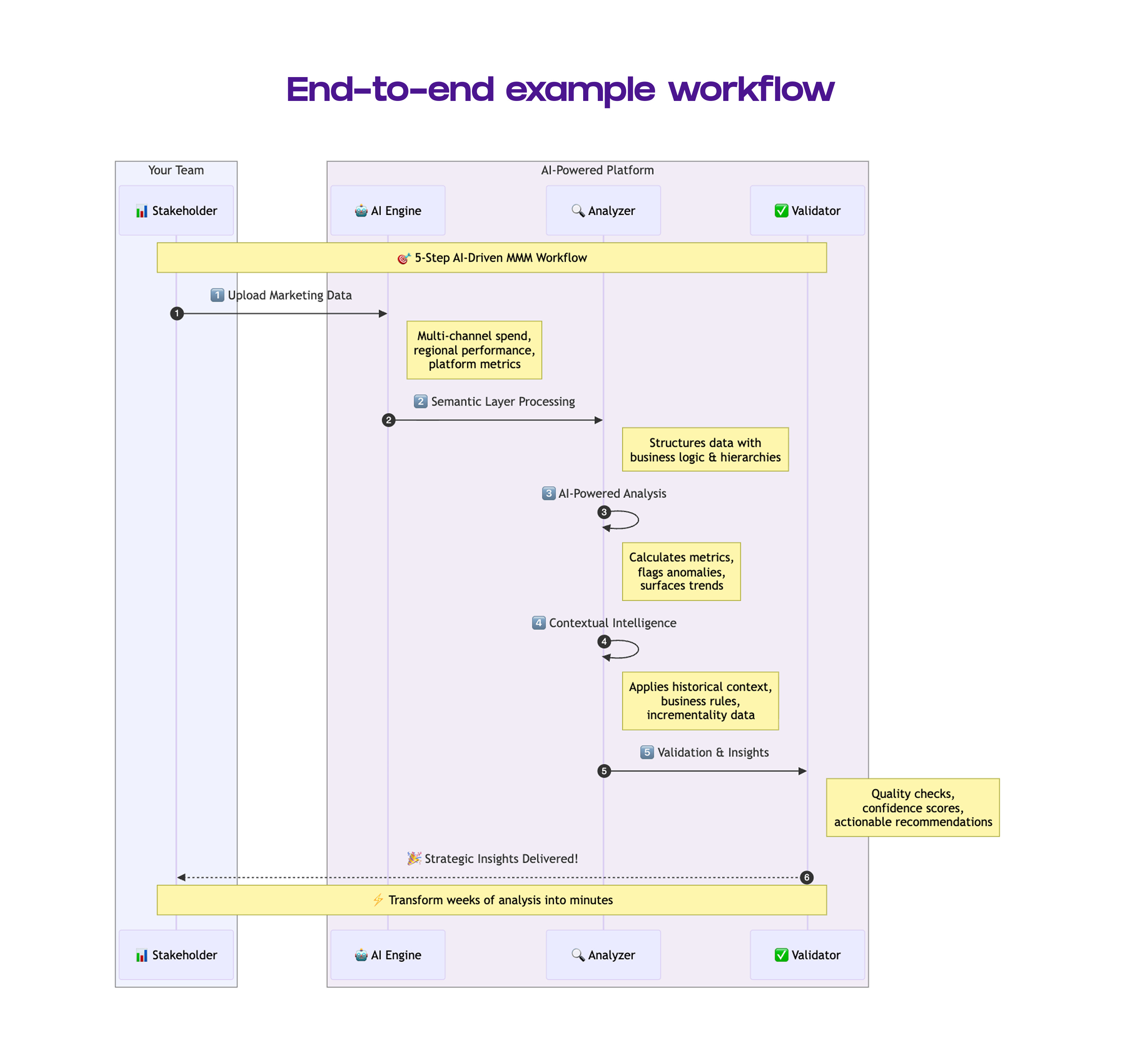
The combination of structured prompts, semantic layers, context engineering, fine-tuning, and modular reasoning ensures the LLM co-pilot generates reliable, actionable insights while minimizing errors and hallucinations.
Reliability & Validation: Guardrails, Testing, and Continuous Improvement
LLM co-pilots accelerate MMM insights but carry risks of misinterpretation, spurious correlations, or overconfident outputs. This unified framework ensures outputs are trustworthy, auditable, and aligned with business objectives, enabling safe and scalable deployment.
Guardrails for Safe and Accountable Outputs
Purpose: Control, constrain, and guide the co-pilot to prevent errors and misalignment.
Below, you can visualise the different types of guardrails that can be implemented for distinct purposes.
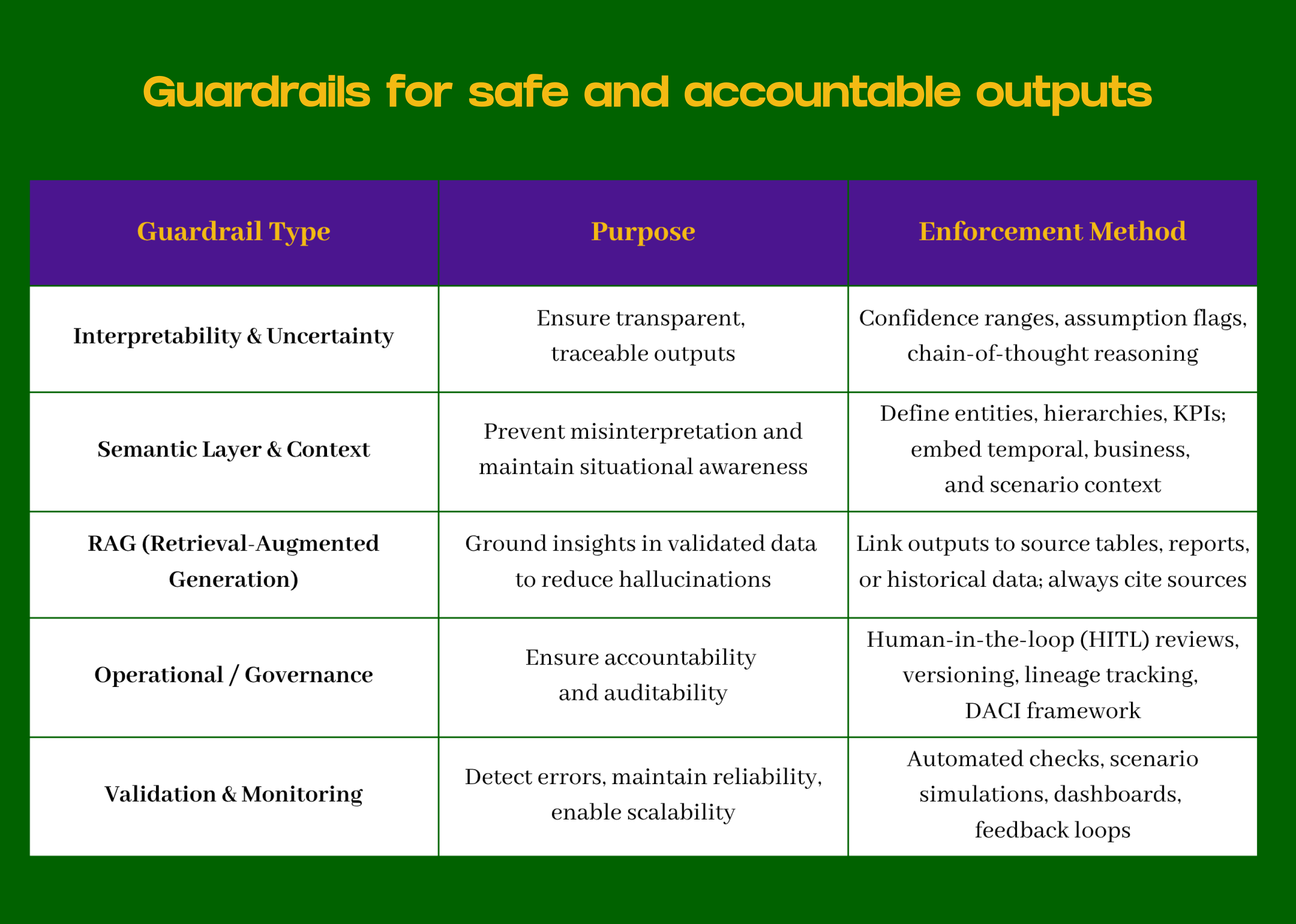
Highlights:
Semantic layers and context engineering ensure correct metric interpretation.
HITL and DACI governance assign ownership and review responsibilities, ensuring auditability.
RAG grounds outputs in factual data, reducing hallucinations.
Testing and Validation
Purpose: Verify correctness, consistency, and alignment with business goals.
User Acceptance Testing (UAT): Compare LLM outputs against expert analyses. Validate KPIs such as CPA, ROAS, CPC, CPM, and contribution.
Scenario Testing: Evaluate co-pilot reasoning on edge cases (e.g., high spend campaigns, seasonal variations).
Error Logging: Maintain a repository of hallucinations, misinterpretations, and KPI deviations. Analyze patterns for continuous improvement.
Monitoring and Metrics
Key indicators to track co-pilot performance:
Accuracy: % of outputs aligned with known MMM results.
Hallucination rate: Frequency of unsupported conclusions.
Coverage: Proportion of channels, segments, and time periods included.
Confidence alignment: Correlation between reported uncertainty and actual error.
Throughput: Time/resource efficiency for generating validated outputs.
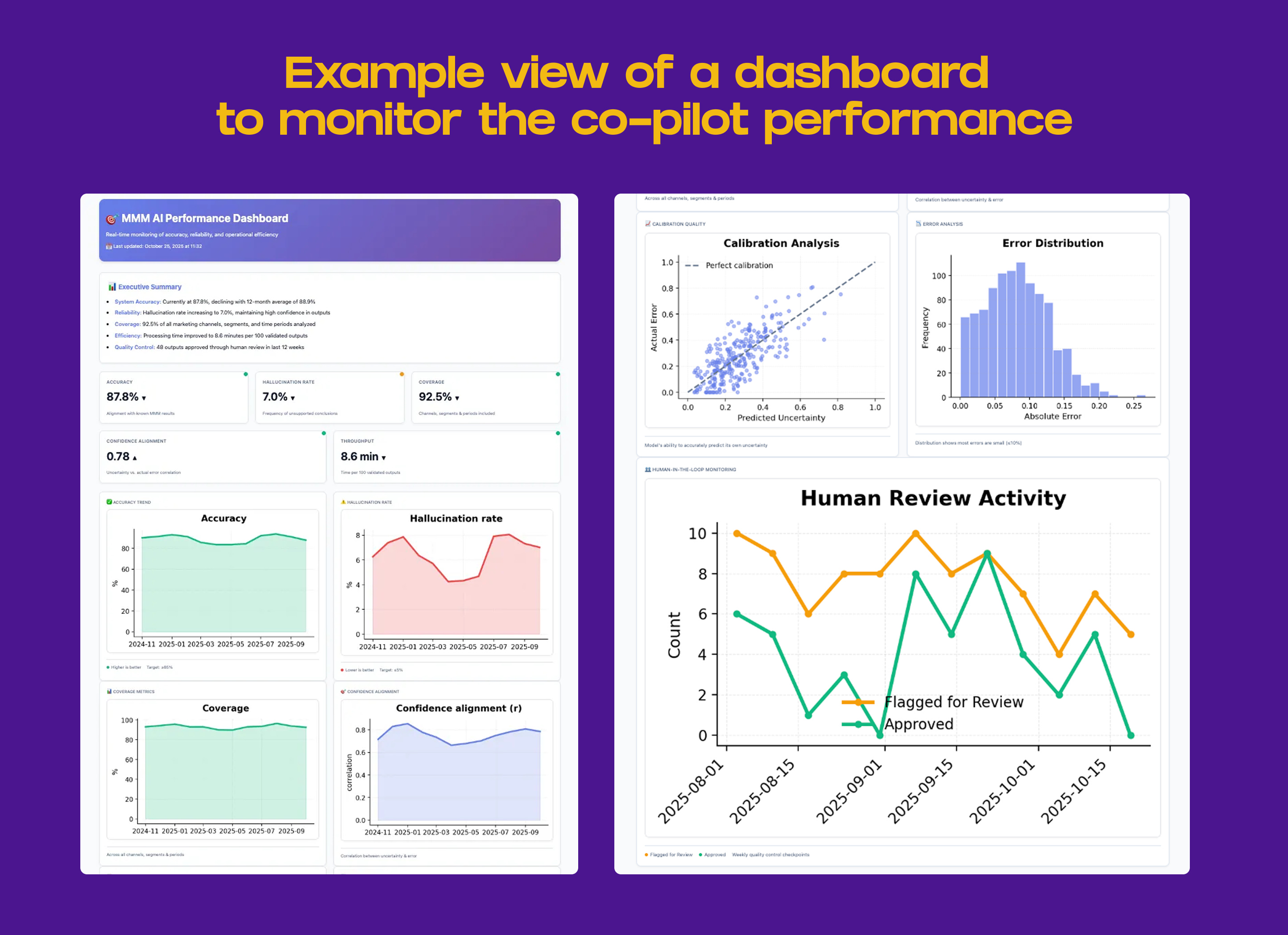
Dashboards can visualize performance trends, confidence ranges, error patterns, and human review checkpoints to support scalable operations.
LLMs Add Speed and Intensity to MMMs, but Guardrails can’t be Skipped
LLM co-pilots can democratize MMM insights - but only if bounded by transparent, testable rules.
When properly designed, they shift marketing analytics from a specialized function into an organization-wide capability: everyone from a CMO to a campaign manager can query performance, simulate ROI, and see what drives growth. Yet democratization without discipline risks confusion. The future of analytics will favor teams that combine accessibility with accountability, co-pilots that explain why they recommend something, not just what to do.
The future of marketing analytics isn’t “AI instead of analysts,” it’s AI guided by analysts.
The future of marketing analytics isn’t “AI instead of analysts,” it’s AI guided by analysts.
Human judgment remains the compass. Data scientists define the metrics, guardrails, and validation logic that keep AI grounded. Analysts interpret nuance that models can’t see - brand shifts, creative fatigue, or cultural moments. The best co-pilots don’t replace human intuition; they amplify it, compressing analysis time while expanding clarity.
“AI that earns trust beats AI that just sounds smart.”
As LLMs move deeper into decision workflows, credibility will matter more than cleverness. Trusted co-pilots will be those that cite sources, quantify uncertainty, and learn from feedback loops. They will act less like automated narrators and more like transparent collaborators, auditable, interpretable, and continuously improving.
The next era of marketing measurement won’t be defined by who uses AI first, but by who uses it responsibly.
Building trustworthy co-pilots means merging the best of both worlds:
The rigor of data science
The discipline of governance
And the human judgment that turns data into direction
If you’ve enjoyed this article, connect to Aditya on Linkedin and subscribe to 021 below:
 | A guest post by
|
Thank you so much! Really insightful !
Since the bottleneck has shifted from analytical speed to inquiry quality, what steps should we take to become the kind of MMM experts the future demands?